

Having read the overview of the EGE it is now possible to proceed with the idea of the internal mechanism. This will lead to specification of the EGE API which is available for use in external applications. This will also show the potential possibilities of the EGE in case, when there will be a number of implementations of particular components types. Below you will find a simple case study illustrating EGE internal mechanism.
Let us assume that:
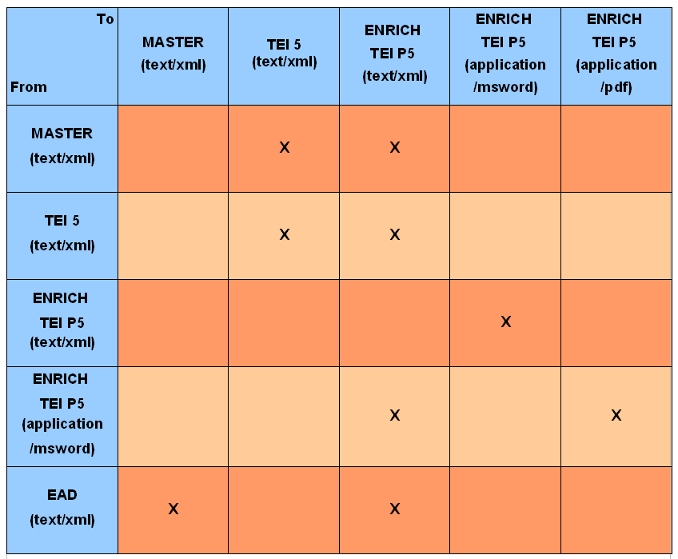
Therefore with the above set of converters it is, for example, possible to convert from MASTER (text/xml) to TEI P5 (text/xml) and from ENRICH TEI P5 (application/msword) to ENRICH TEI P5 (application/pdf), but it is not possible to convert from EAD (text/xml) to ENRICH TEI P5 (application/pdf) or from TEI P5 (text/xml) to ENRICH TEI P5 (application/pdf). Additionally, we may imagine a converter from TEI P5 (text/xml) to TEI P5 (text/xml) which could simply clean the given input data of redundant information or restructure it in some pre-determined manner. Moreover, we could imagine a converter which will be independent of the format and will focus only on the IMT, e.g. converter which converts everything from (application/msword) to (application/pdf), although at this moment such feature is not supported.
Based on these three assumptions, let us build a directed graph of possible conversion, just as it is being built in the EGE. The nodes in the graph indicate the converters (with input format, action and output format specified) and the directed edges (arcs) will connect the converters between each other. The arc from converter A to converter B exists if and only if the output data format and IMT of the converter A is identical as the input data format and IMT of the converter B. Based on that we have the following graph:
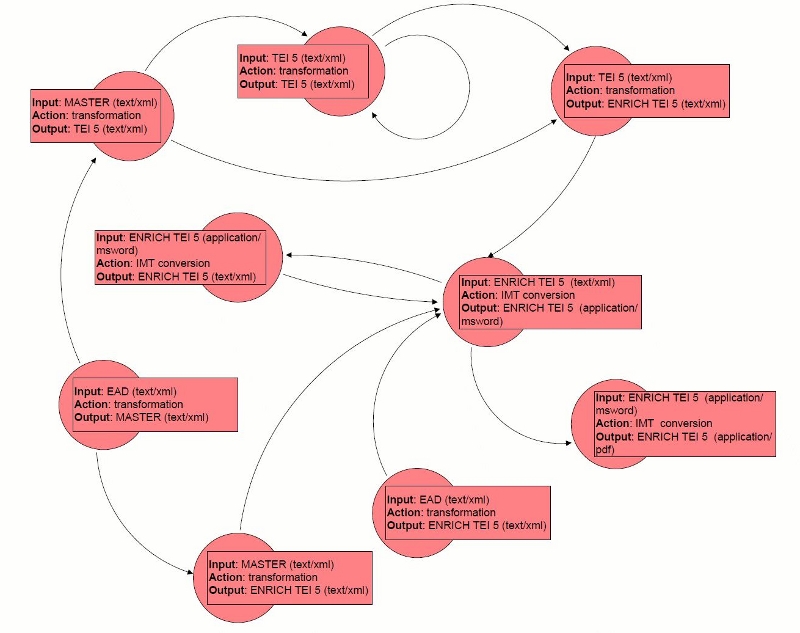
With the above graph and the format and IMT of the input data (recognized by one of the recognizers and then validated or given by the end user directly) we may determine the possible conversion paths for the input data. The simplest version of the algorithm to determine possible paths is as follows:
There are some issues that the algorithm (and the EGE user to a certain degree) has to take into account:
Summarizing: in the EGE each converter provides a set of conversion actions with specified input and output data, e.g. an action in which converter can use to convert from ENRICH TEI P5 format in text/xml IMT to ENRICH TEI P5 format in application/msword IMT. All conversion actions are connected through their input and output formats and forms convert graph. That representation enables the provision of a mechanism for converting data in a specified format to other another supported format in multiple ways - by searching paths in graph. Paths of conversion can be then be chosen by users through an implemented interface (e.g. GUI or web application forms).
Before converting each input data its IMT may be recognized by Recognizer component. Its format (e.g. ENRICH TEI P5) may then be validated by the Validator component. Alternatively the application which uses EGE may ask the user directly for the input IMT and data format.